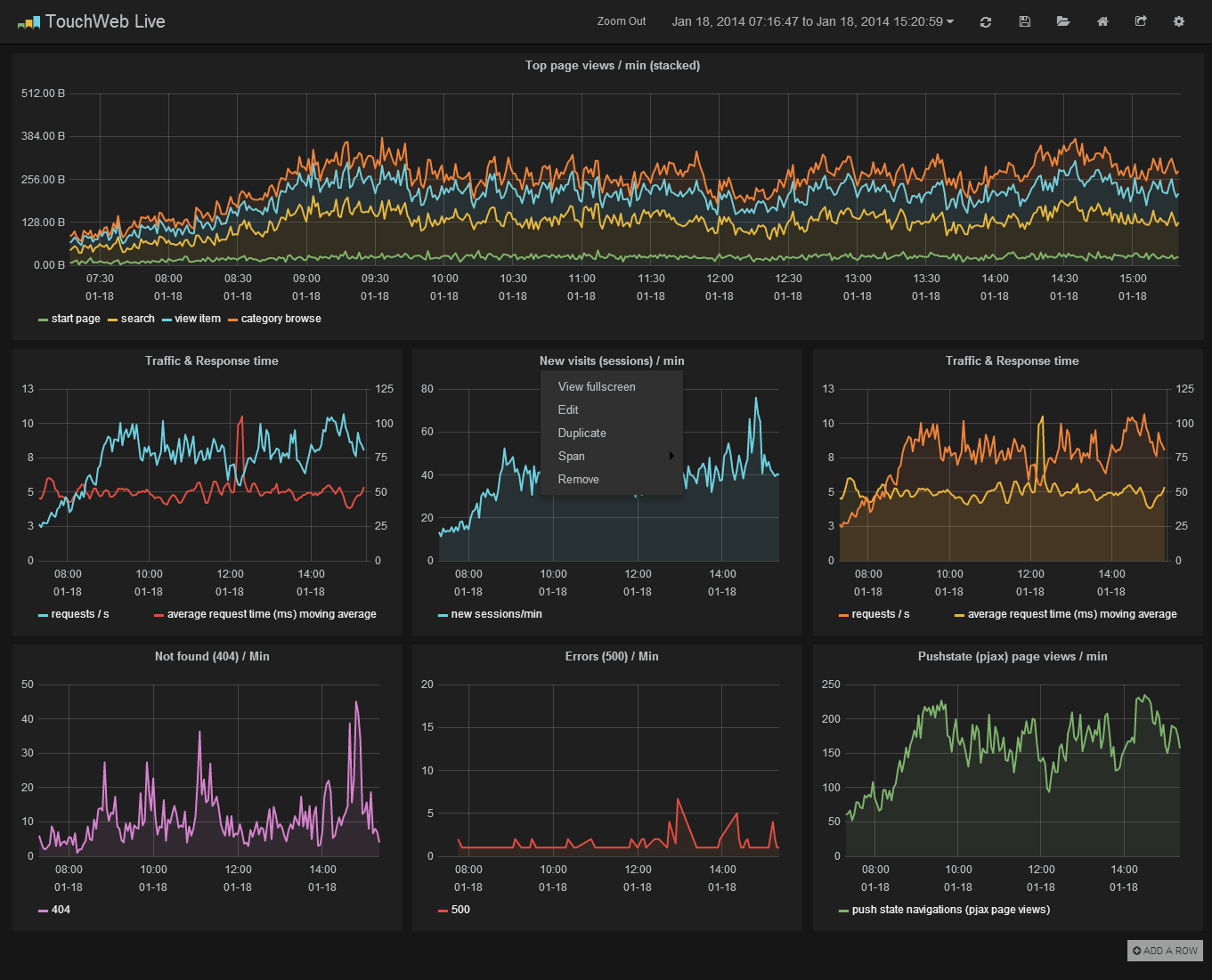
I have been spending a lot of time thinking about and playing with Metrics. It started as an innovation project at my current customer but I have had a hard time not to think and work on it on my spare time.

It all centers around a small metrics framework that pushes application performance timing, health, and most importantly business counters and metrics to a backend system called Graphite. Graphite is a real time scalable graphing system that can handle a huge amount of metrics. You can define flexible persistence and aggregation rules, and most importantly you can plot your metrics in graphs using a large amount of flexible functions. Functions that can combine metrics, stack metrics from different servers, calculate percentiles, standard deviation, moving average, summarize, filter out outliers, etc.
I wrote a small metrics framework that can handle counters, gauges and timers. These are aggregated and sent to Graphite via UDP every x seconds (depending on how real time your want your metrics).


Examples of how to increment a counter and time a lambda function. The real power comes from how graphite can aggregate metrics from all production servers, compare or summarize them.
Example:

aliasByNode(test.servers.*.gauges.cpu.processor_time, 2)
With a single line like this we can stack cpu usage on all test servers (notice the wild card in the above expression). New test servers would automatically appear in the above graph.
You can also aggregate metrics from different servers like this:
sumSeries(carbon.agents.*.metricsReceived)
Graphite gives you a lot control of how to persist and aggregate metics in the backend as well.
storage-schemas.conf
[stats]
pattern = ^prod.*
retentions = 10s:6h,1min:7d,10min:5y
This translates to: for all metrics starting with 'prod' , capture:
- 6 hours of 10 second data
- 1 week of 1 minute data
- 5 years of 10 minute data
In another config file you specify how metrics should be rolled up (for example how 10 second data should be rolled up / aggregated to 1 minute data). For example you want counters to be summed, and timings to be averaged.
You can also have a graphite aggregator that aggregates and persists aggregated metrics. For example most of the time you don’t want to see business metrics split per server so to make it easier to plot graphs you can have graphite create and persist an aggregated metric for you (this could be done by graph functions as well). This is can be done using format rules like this:
<env>.applications.<app>.all.counters.<metric_name> (60) = sum <env>.applications.<app>.*.counters.<metric_name>
Given metrics with names like:
prod.applications.member-notifications.server-1.counters.order_mail_sent
prod.applications.member-notifications.server-2.counters.order_mail_sent
prod.applications.member-notifications.server-3.counters.order_mail_sent
prod.applications.member-notifications.server-4.counters.order_mail_sent
Graphite will every 60 seconds summarize the counter received for each server and generate a new metric with name name “all” instead of the server name.
Graphite is bundled with a web application that lets you view and create graphs and dashboards (shown in the first screenshot in this blog post). The standard graphing component utilizes image based graphs. There is an experimental canvas based graph as well but it is not very good. Luckily there are a great number of alternative frontends for graphite that support live graph dashboards that use canvas or svg graphics. I like
Giraffe, but its styling was not very nice, so after a quick css makeover it looked like this:

With Giraffe and other svg/canvas based dashboards and graphing engines you can get real time moving graphs (graph data is fetched from graphite HTTP API).
There is a large community built around Graphite, with everything from metric frameworks, machine metric daemons, alternative frontends, support tools and integration with monitoring systems like Nagios and Ganglia.
Graphite is not easy to install and setup (do not even try to get it running on windows). And it takes time to understand it’s persistence model and configuration options. It is extremely specialized to do one thing and one thing only: persist, aggregate and graph time series data. This specialization is also it’s strength as a single Graphite server can handle millions of metrics per minute and store them in a very optimized format (12 bytes per metric per time interval). So 6 hours of 10 second data is just 2160 bytes per distinct metric.
Lets say you have 10 servers with 2 applications, each application sends 200 distinct metrics (business counters, performance timings, operation metrics, etc) every 10 seconds. The storage required for 6 hours of data: 10 (servers) * 2 (applications) * 200 (distinct metrics) * 6 (measures per minute) * 60 (minutes) * 6 (hours) = 8640 KB
Metrics older than 6 hours will be rolled up into one minute buckets which will reduce storage to 1/6th of the above.
Links:
Update (2014-02-23):
I have since this post created a new graphite dashboard replacement called Grafana, visit
grafana.org for more info!.